Wat zijn Service Level Objectives (SLO's) en waarom zou ik ze meten?

Published on 23 November 2023 by Zoia Baletska
Heb je je ooit afgevraagd waarom sommige softwaretoepassingen beter presteren dan andere? Het antwoord is eenvoudig: ze hebben goed gedefinieerde Service Level Objectives (SLO's).
SLOs in Agile Analytics
SLO's zijn een kritisch onderdeel van Site Reliability Engineering (SRE) en definiëren het doelniveau van servicekwaliteit dat een systeem zou moeten bieden. In deze verklaring zal ik uitleggen wat SLO's zijn, waarom ze belangrijk zijn en voorbeelden geven van veelvoorkomende SLO's.
Service Level Objectives, afgekort als SLO's, zijn specifieke, meetbare doelen die softwareontwikkelingsteams helpen ervoor te zorgen dat hun systemen correct en efficiënt functioneren. Het primaire doel van SLO's is het vaststellen van een drempelwaarde voor de acceptabele servicekwaliteit van een systeem, meestal uitgedrukt als een percentage van de uptime of responstijd. Door de prestaties van een systeem te meten aan de hand van SLO's, kunnen teams bepalen of hun systemen de beoogde serviceniveaus halen of verbeterd moeten worden.
Verschillende soorten SLO's kunnen worden gedefinieerd op basis van verschillende aspecten van serviceprestaties. Hier zijn enkele veelvoorkomende types:
Beschikbaarheid SLO's:
- Definitie: Meten het percentage van de tijd dat een service beschikbaar en operationeel is.
- Voorbeeld: Een beschikbaarheid van 99,9% betekent dat de dienst maximaal 8,76 uur per jaar niet beschikbaar mag zijn.
Latency SLO's:
- Definitie: Richten zich op de tijd die een service nodig heeft om te reageren op een verzoek of om een specifieke actie uit te voeren.
- Voorbeeld: Een latentie SLO zou kunnen specificeren dat 95% van de verzoeken verwerkt moeten worden in minder dan 100 milliseconden.
Doorvoer SLO's:
- Definitie: Meten het aantal operaties dat een service kan afhandelen binnen een gespecificeerd tijdsbestek.
- Voorbeeld: Ervoor zorgen dat een webservice 1000 verzoeken per seconde kan afhandelen zonder dat de prestaties verslechteren.
Foutenpercentage SLO's:
- Definitie: Richten zich op het percentage verzoeken dat resulteert in fouten of mislukkingen.
- Voorbeeld: Het foutpercentage onder 0,5% houden geeft een hoog betrouwbaarheidsniveau aan.
Twee van de meest voorkomende SLO's zijn beschikbaarheid en latentie. Laten we ze nader bekijken en configureren in Agile Analytics.
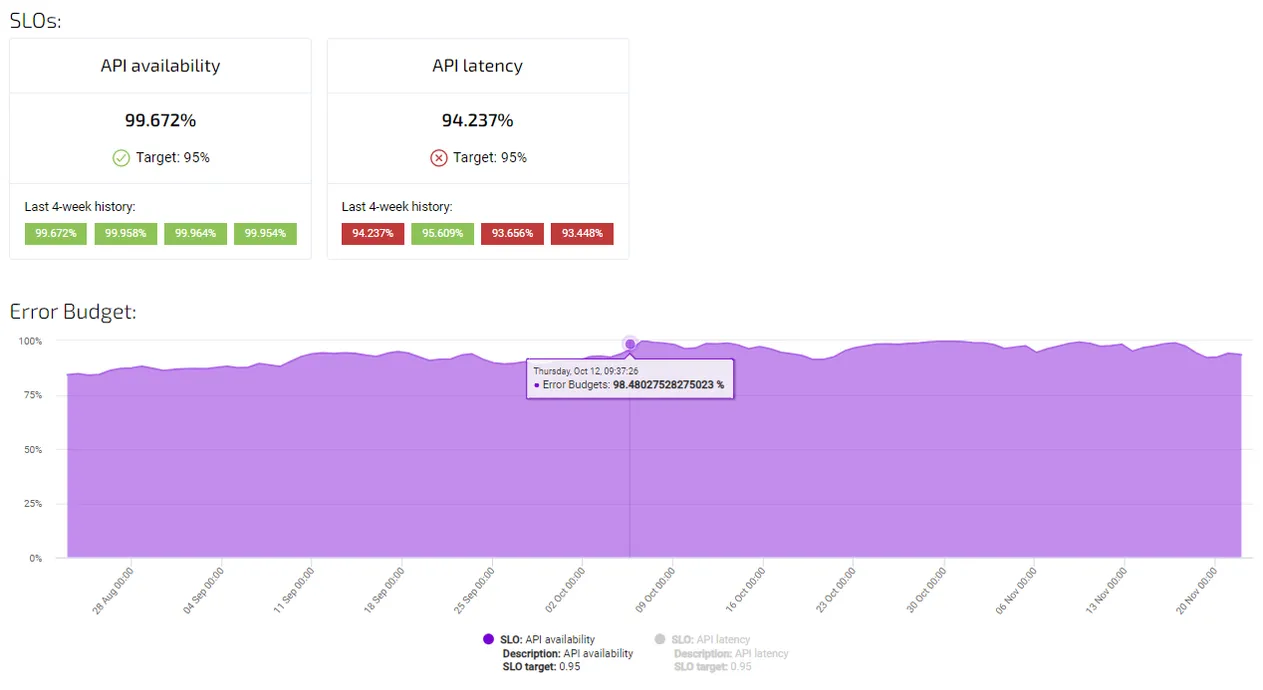
Met Agile Analytics kunt u eenvoudig Service Level Objectives voor uw diensten instellen, beheren en waarschuwen wanneer een SLO zijn doel voorbij schiet of wanneer het bijbehorende foutbudget op is.
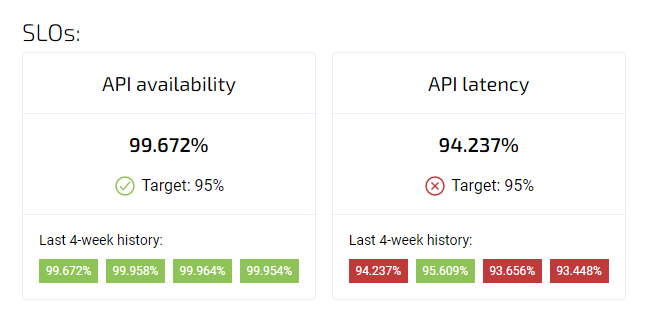
Beschikbaarheid SLO's
Een Beschikbaarheid SLO bepaalt het minimaal aanvaardbare niveau van uptime voor een service gedurende een specifieke periode. Bijvoorbeeld, een e-commerce website kan een beschikbaarheids-SLA van 99,9% hebben, wat betekent dat de website elke maand minstens 99,9% van de tijd beschikbaar moet zijn. Deze SLO's zijn van essentieel belang om te waarborgen dat klanten toegang hebben tot de service wanneer ze die nodig hebben en kunnen teams helpen bij het prioriteren van inspanningen om de uptime te verbeteren.
Het is eenvoudig om het volgen van een SLO voor beschikbaarheid in Agile Analytics in te stellen
bijhouden beschikbaarheid SLO in Agile Analytics
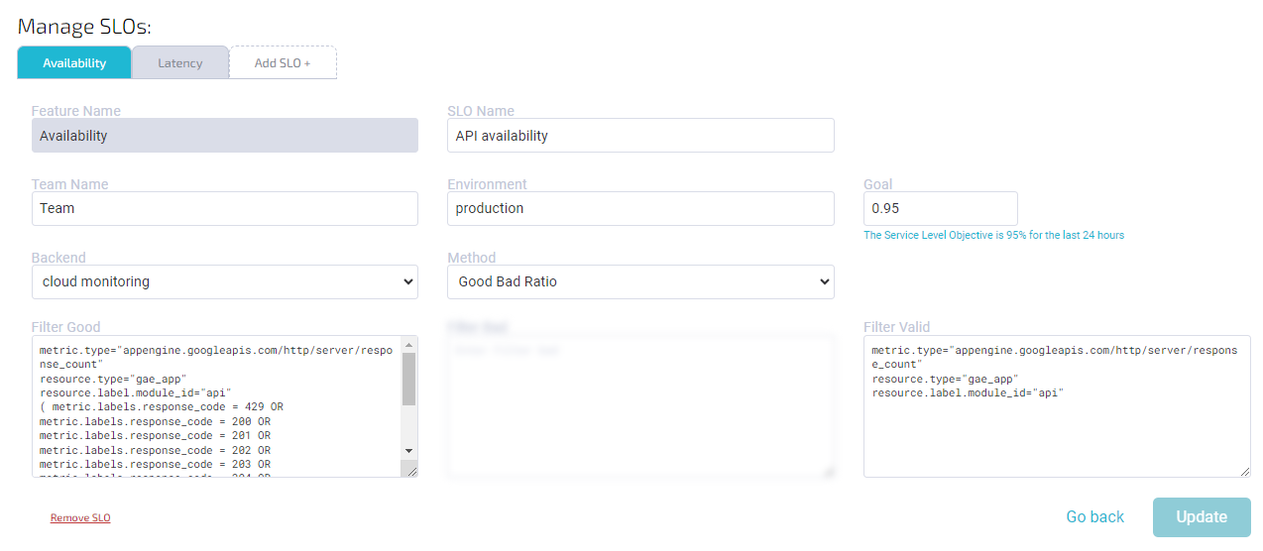
Gebruikelijke filters om beschikbaarheid te meten (goed-slecht verhouding):
Filter goed:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16project="google-project-name" metric.type="appengine.googleapis.com/http/server/response_count" resource.type="gae_app" resource.label.module_id="module-name" (metric.labels.response_code = 429 OR metric.labels.response_code = 200 OR metric.labels.response_code = 201 OR metric.labels.response_code = 202 OR metric.labels.response_code = 203 OR metric.labels.response_code = 204 OR metric.labels.response_code = 205 OR metric.labels.response_code = 206 OR metric.labels.response_code = 207 OR metric.labels.response_code = 208 OR metric.labels.response_code = 226 OR metric.labels.response_code = 304)
Filter geldig:
1 2 3 4project="google-project-name" metric.type="appengine.googleapis.com/http/server/response_count" resource.type="gae_app" resource.label.module_id="module-name"
Latency SLOs
Een Latency SLO definieert de maximaal aanvaardbare reactietijd voor een dienst. Een bankapplicatie kan bijvoorbeeld een Latency SLO van 500 ms hebben, wat betekent dat de applicatie binnen 500 ms of minder moet reageren op verzoeken van gebruikers. Latency SLO's zijn essentieel om ervoor te zorgen dat diensten snel reageren, wat de gebruikerservaring en tevredenheid kan verbeteren.
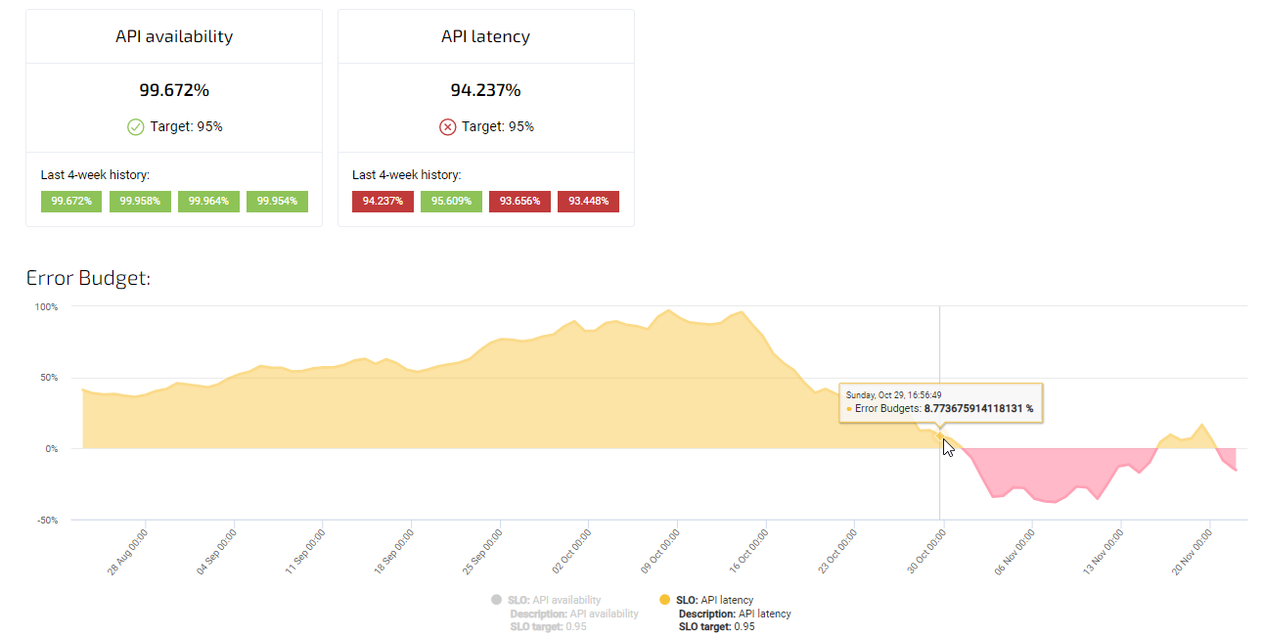
latency SLO bijhouden in Agile Analytics
Setting up a Latency SLO in Agile Analytics is super easy
Hier is een gebruikelijke Latency SLO (Distribution cut) opstelling in Agile Analytics:
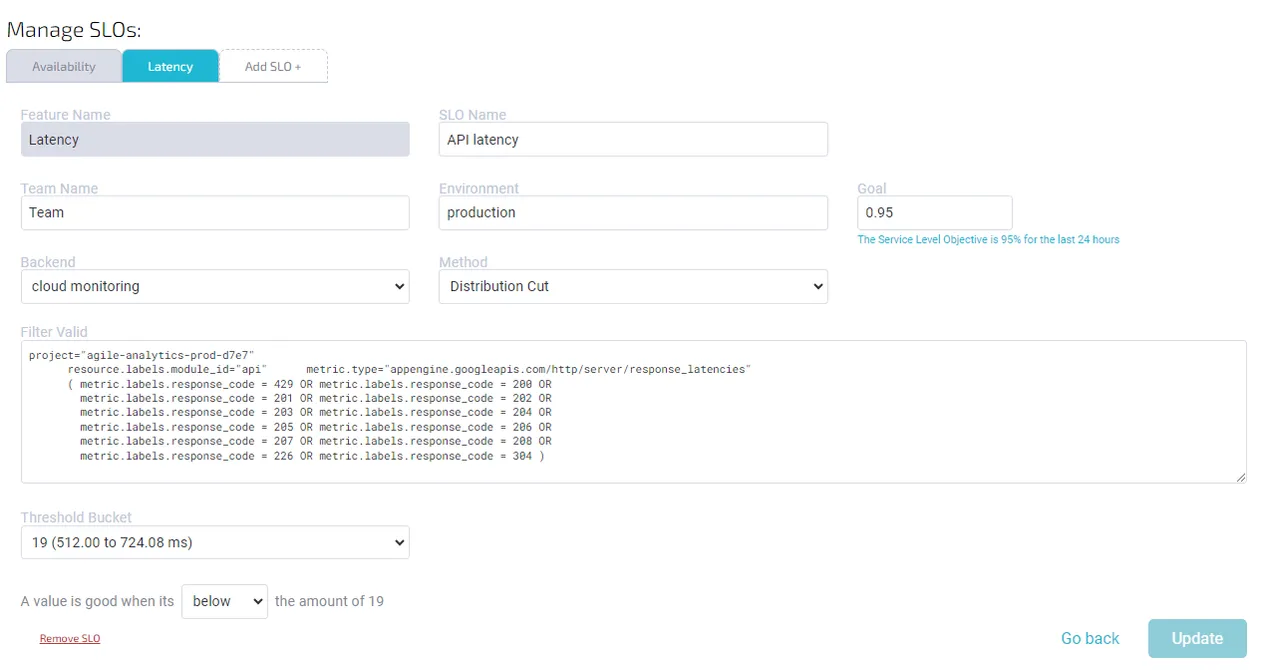
Filter geldig:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15project="google-project-name" resource.labels.module_id="module-name" metric.type="appengine.googleapis.com/http/server/response_latencies" (metric.labels.response_code = 429 OR metric.labels.response_code = 200 OR metric.labels.response_code = 201 OR metric.labels.response_code = 202 OR metric.labels.response_code = 203 OR metric.labels.response_code = 204 OR metric.labels.response_code = 205 OR metric.labels.response_code = 206 OR metric.labels.response_code = 207 OR metric.labels.response_code = 208 OR metric.labels.response_code = 226 OR metric.labels.response_code = 304)
Threshold bucket: 19 Good Below Threshold: True
Conclusie
"Meten is weten" - Nederlands spreekwoord.
Uiteindelijk is het glashelder dat SLO's een cruciaal onderdeel zijn van het in de lucht houden van je softwareservices. Met beschikbaarheid en latentie als toppers, kun je snel meten hoeveel tijd je service op de bank doorbrengt en hoe snel hij in actie komt als iemand hem nodig heeft. Met Agile Analytics kun je SLO's sneller bijhouden dan Usain Bolt op de 100 meter sprint, krijg je direct inzicht in wat er aan de hand is en transformeer je je diensten in een lean, mean performance machine. Dus, waar wacht je nog op? Probeer de 60-dagen gratis proefversie van Agile Analytics en breng uw softwarediensten vandaag nog in topvorm!
Implementeer Service Level Objectives
Stel Service Level Objectives in met behulp van gebruiksvriendelijke interface van Agile Analytics. Operationeel in een mum van tijd!





